Personalizing RLHF with Variational Preference Learning
This research project was conducted as part of COMPSCI 602: Research Methods in Empirical Computer Science, under the guidance of Professor David Jensen.
Abstract from:
Replication of “Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning”
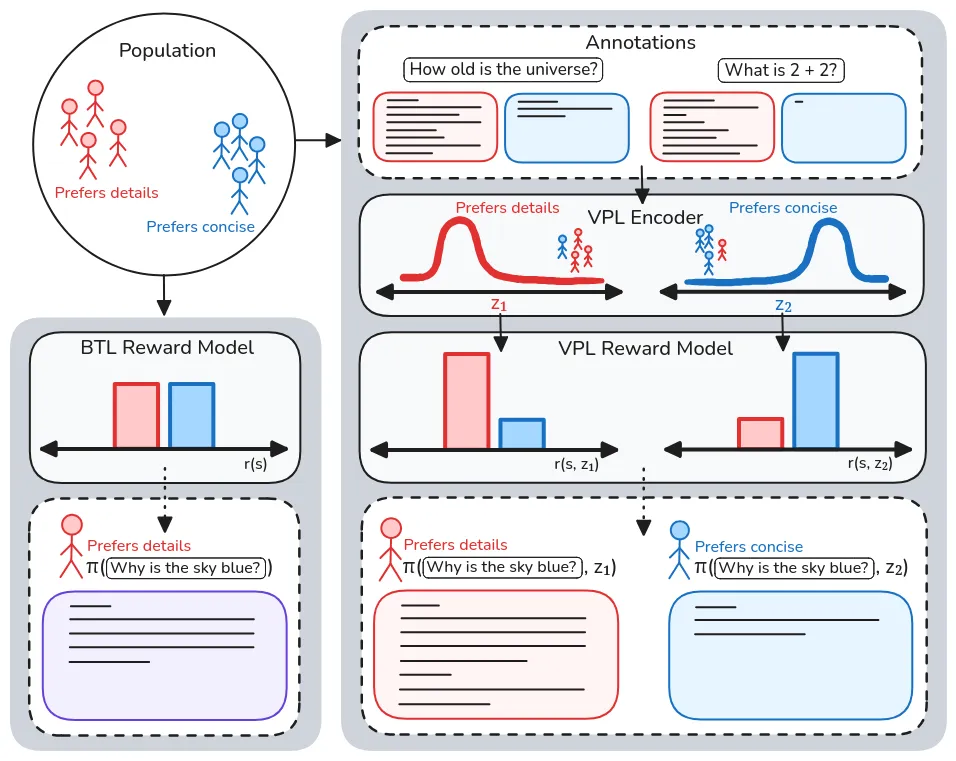
Reinforcement Learning from Human Feedback (RLHF) methods have grown to be a cornerstone tool for aligning models to human-centric values. Current RLHF techniques, which rely on unimodal reward models such as the Bradley-Terry-Luce (BTL) model, struggle to account for the complex, multi-modal nature of human preferences in diverse populations. This work explores a proposed solution to these issues coined as Variational Preference Learning (VPL). VPL emphasizes its ability to infer and adapt to individual user contexts through a latent variable formulation. We investigate the core hypothesis that VPL can effectively capture multi-modal reward functions, demonstrating its capacity to recover diverse preference distributions more accurately than existing methods. Experimental results show that VPL significantly outperforms the BTL baseline in recovering complex, multi-modal reward functions. These findings suggest that VPL is a promising approach for pluralistic alignment, offering improved alignment to diverse values and preferences in RLHF systems.